در این آموزش به مروری بر یکی از ابزارهای پردازش زبان طبیعی (NLP) مبتنی بر یادگیری ماشین و در نوع خاص یادگیری عمیق میپردازیم. Word2Vec ابزاری است که توسط Mikoilov در سال 2008 معرفی شد و چرخ متحرک بسیاری از پژوهشها و برنامههای تجاری است.
این سلسله مقالات به منظور تمرکز بر بخشهای جذاب و مهم ساخت یک مدل word2vec در تنسورفلو ارائه میشوند.
طرح این کار با بیان انگیزه بازنمایی لغات به صورت برداری آغاز میشود. سپس نگاهی بهبه پشتصحنهی این مدل و چگونگی آموزش آن میاندازیم. همچنین یک پیادهسازی ساده از مدل را تنسورفلو انجام میدهیم. در نهایت نگاهی به راههای ایجاد نسخهای ساده در مقیاس بهتر میاندازیم.
مقدمه
شاید ایدهی اولیه word2vec از یک روش معمول در فهم متون و یا لغات ناآشنا الهام گرفتهشده است. یعنی این ایده که در هنگام مواجهه با یک لغت ناآشنا در متن (بهخصوص متون زبان خارجی) با توجه به سیاق مطلب و سایر واژگان همسایگی لغت ناآشنا، میتوان تا حدود بسیار خوبی تقریبی از معنی و مفهوم آن واژه و یا حتی نقش آن به دست آورد.
اما شاید مهمترین ایده و راهکار ارائهشده Word2Vec تبدیل واژگان به بردار و انتقال آن به فضای برداری است که امکان پردازش لغات و متنها را با ابزارهای یادگیری ماشین امکانپذیر و آسان میسازد.
در این آموزش و سلسله مقالاتی که در ادامه آن منتشر خواهد شد؛ به بررسی معماریهای Word2Vec یعنی شبکه عصبی Skip gram و CBOW ( کیسه لغات پیوسته) خواهیم پرداخت. درنهایت در مقالات بعد به پیادهسازی آنها در تنسورفلو و استفاده و بارگیری مدلهای از پیش آموخته خواهیم پرداخت.
بازنمایی برداری لغات
مدل Word2vec در حقیقت مدلی است که برای یادگیری بازنماییهای برداری از لغات استفاده میشود که در اصطلاح word embeddings نامیده میشود.
چرا از word embeddings استفاده میکنیم؟
سامانههای پردازش صدا و تصویری که دقت بالایی دارند با استفاده از مجموعه دادگانی غنی و با ابعاد بالا کار میکنند که در آنها تصاویر بهصورت بردارهای از شدت نورهای پیکسلهای خام و اصوات بهصورت ضرایبی از شدت توان، کدبندیشدهاند. برای کارهایی مانند تشخیص گفتار، ما میدانیم که تمامی دانش لازم برای انجام موفق این کار، در همان کدگشایی دادگان خام است (چون انسان این کارها را بهخوبی از دادگان خام انجام میدهد).

سامانههای پردازش زبان طبیعی سنتی با لغات بهصورت نمادهای گسستهی اتمی (غیرقابل تجزیه) رفتار میکنند، مثلاً گربه میتواند به شکل Id537 و سگ بهصورت Id143 بازنمایی شود. این کد سازیها به صورت دلخواه است و هیچگونه اطلاعات مفیدی که ممکن است در بین این لغات وجود داشته باشد را فراهم نمیسازد. به همین دلیل پژوهشگران درحالتوسعه مدلهایی هستند که این روابط حاکم بین واژگان را در بازنمایی آنها تعبیه سازد.
Word2vec یک مدل پیشگو به منظور یادگیری تعبیه سازی لغت از متن خام است که از لحاظ پیچیدگی محاسباتی بسیار کاراست. به بیان ساده تر در این مدل قرار است روابط بین لغات از نحوه قرارگیری آنها در متون استخراج شود. Word2vec به دو صورت است. مدل کیسه لغات پیوسته (CBOW) و اسکیپ گرام (Skip Gram).
از لحاظ الگوریتمی این دو روش شبیه هم هستند با این تفاوت که CBOW لغات هدف را از روی لغات متن ورودی پیشبینی میکند ولی اسکیپ گرام به صورت برعکس از روی لغات مرجوعه هدف، لغات ورودی را پیشبینی میکند.
برعکس کردن این چرخه دلخواه به نظر میرسد ولی از لحاظ آماری CBOW تأثیر نرمی بر روی همه اطلاعات توزیعی دارد (با رفتاری شبیه به یک مشاهده بر روی کل متن) و درکل این روش میتواند روشی مفید برای استفاده در مجموعه دادگان کوچکتر باشد. اما اسکیپ گرام با هر زوج محتوا-هدف بهصورت یک مشاهده جدید رفتار میکند و در مجموعه دادگان بزرگتر بهتر جواب میدهد.
ما در ادامه ابتدا بر روی مدل اسکیپ گرام تمرکز خواهیم کرد.
در مدل زبان احتمالاتی عصبی (Neural probabilistic language) معمولاً با استفاده از اصل بیشینه درستنمایی آموزش داده میشوند تا احتمال وقوع لغت بعدی (برای هدف) را برای لغات دادهشدهی h پیشین در گزارهی تابع softmax بیشتر کنند.
که در این گزاره میزان سازگاری لغت را با محتوای h بیان میکند. (معمولاً یک حاصلضرب داخلی (نقطهای) استفاده میشود). ما این مدل را با بیشینه کردن لگاریتم درستنمایی بر روی مجموعه دادگان آموزش میدهیم. یعنی با بیشینه کردن
فایده این کار این است که مدل نرمال شدهی احتمالاتی برای مدل کردن زبانی به دست میآید.
اگرچه ازلحاظ محاسباتی بسیار پرهزینه است چرا که در هر گام از آموزش، برای محاسبه و نرمالسازی هر احتمال نیازمند استفاده از امتیاز همهی لغات موجود در محتوای h هستیم.
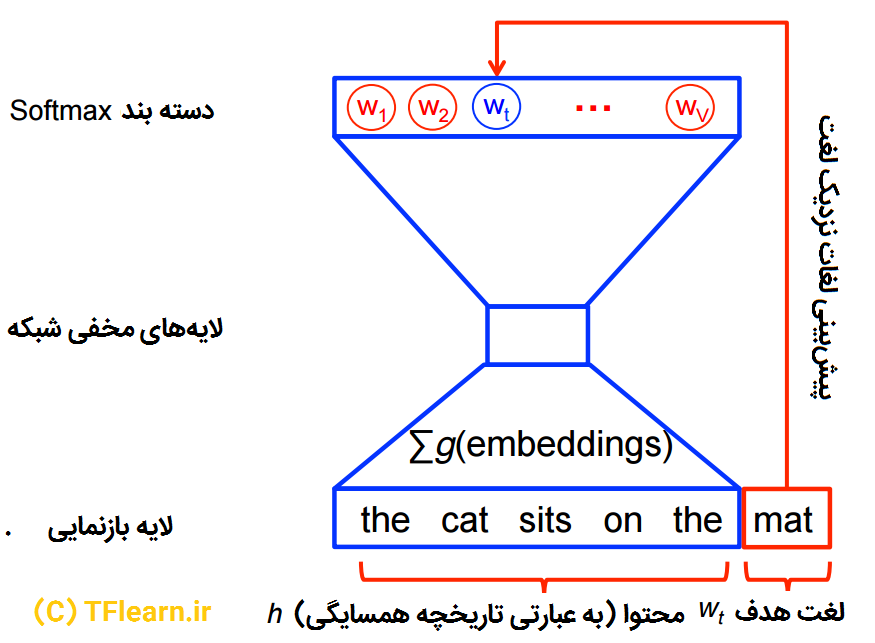
به بیان سادهتر فرض کنید ما میخواهیم یک شبکه عصبی ساده را با یکلایه پنهان آموزش دهیم تا یک کار خاص را انجام دهد اما درنهایت ما شبکه را استفاده نمیکنیم بلکه از وزنهای آموزش دادهی آن بهره خواهیم گرفت. در ادامه خواهید دید که چگونه این وزنها در حقیقت زبانی میانی برای توصیف و ارائه بردارهای لغات خواهند شد.
در حقیقت از این ترفند در استخراج بدون ناظر ویژگیها استفاده میشود جایی که شما یک اتوانکودر را آموزش میدهید تا یک بردار ورودی را در لایههای مخفی فشرده کند و مجدداً در لایه خروجی از فشردهسازی خارج نماید. پس از آموزش این شبکه ، بدون داشتن دادههای برچسب خورده شما ویژگیهای خوبی را استخراج کردید. برای مطالعه بیشتر به مطلب پیاده سازی خودکدگذار در TensorFlowمراجعه کنید.
در بخش بعدی به بررسی دقیق تر مدل خواهیم پرداخت.
ما را با نظرات و پیشنهادهای خود در هر چه بهتر شدن مطلب یاری کنید.