
بازشناسی ارقام دست نویس (دستنوشته) از ابتدایی ترین و پر کارترین مسایل در زمینه یادگیری ماشین است. مجموعه داده های بسیاری در این زمینه به وجود آمده است که مشهورترین آنها مجموعه MNIST است. در ادامه به پیاده سازی یک مدل softmax برای بازشناسی MNIST میپردازیم.
بازشناسی ارقام دست نویس MNIST در TensorFlow (برای تازهکاران یادگیری ماشین)
این آموزش برای آن دسته از مخاطبانی است که بهتازگی قصد آموختن یادگیری ماشین و تنسورفلو را کردهاند. ممکن است بخشهایی از این مطلب در مقالات و مطالب قبلی نیز بیانشده باشند که برای اطلاعات تکمیلیتر به آنها ارجاع داده خواهد گشت. اگر شما میدانید که MNIST چیست و با شبکه عصبی چندلایه (MLP) و رگرسیون SOFTMAX آشنایی دارید ، بهتر است آموزشهای دیگر را دنبال کنید.
قبل هر چیز اگر تنسورفلو را نصب نکردهاید به بخش آموزش نصب مراجعه کنید و درصورتی که بر روی رایانه شما نصب است، از صحت نصب آن مطمئن شوید.
بهطور معمول در آموزشهای زبانها و ابزارهای برنامهنویسی و یا برنامهسازی، سنتی دیرینه وجود دارد و آن سنت این است که اولین مثالی که آموخته میشود، برنامه چاپ “HELLO WORLD” است. همانند زبانهای برنامهنویسی که مثال Hello world دارند، یادگیری ماشین نیز مسئلهای ابتدایی دارد که از آن با نام MNIST یادد میشود.
Mnist یک مجموعه داده ساده در زمینه بینایی ماشین(کامپیوتر) است. این مجموعه داده شامل تصاویری از ارقام دستنویس انگلیسی مانند تصاویر زیر است:

همچنین در این مجموعه، برچسبهایی برای هر تصویر وجود دارد که بیانگر این است که هر تصویر نمایان گر چه رقمی است.
برای مثال این برچسبها برای تصاویر بالا به ترتیب از چپ به راست عبارتاند از ۵و۰و۴و۱٫
در این آموزش ، ما قصد داریم مدلی را آموزش دهیم که به نوعی به تصاویر نگاه کند و بگوید که این تصاویر بیانگر چه ارقامی هستند. هدف از این آموزش این نیست که یک مدل واقعاً پیچیده را که کارایی چشمگیر( state-of-the-art) دارد، آموزش دهیم—گرچه در آموزشها و مقالات دیگر این کار را به شما آمورش خواهیم داد — در حقیقت هدف این مطلب، برداشتن گامی کوچک در راستای استفاده از تنسورفلو است. بهطور جزئیتر، قصد داریم که با یک مثال خیلی ساده به نام رگرسیون softmax شروع کنیم.
کد استفادهشده برای این آموزش بسیار کوتاه است و همه چیزهای جالب کار، در سه خط کد اتفاق میافتد. هرچند درک ایده پشت آن بسیار مهمتر است، یعنی چگونه TensorFlow کار میکند و مفاهیم هسته یادگیری ماشین. به همین خاطر قصد داریم که خیلی با دقت با کد کار کنیم.
دادههای MNIST
دادههای MNIST بر روی وبسایت پروفسور Yann LeCun قرارگرفته است. برای راحتی شما، تعدادی کد پایتون در تنسورفلو قرار دادهشده که به صورت خودکار مجموعه داده را دانلود و نصب مینماید .شما میتوانید مجموعه دادهها با استفاده از کد زیر فراخوانی و دانلود نمایید.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)دادههای دانلود شده به سه بخش تقسیم میشوند، ۵۵٫۰۰۰ نمونه (داده) به عنوان مجموعه داده آموزشی ، ۱۰۰۰۰۰ نمونه برای تست و ۵۰۰۰ نمونه برای اعتبار سنجی. این تقسیم بسیار مهم است ، در یادگیری ماشین بسیار ضروری است که دادهها را جدا کرده که بیشتر از حدی مدل آموزش داده نشود تا مطمئن شویم که مدلی که آموزش دیده است در واقع تعمیمپذیر است یا به بیان سادهتر مدل آموزش دادهشده به صورت طوطیوار عمل نمیکند که فقط قادر به پاسخگویی نمونههای آموزش دیده باشد و در مقابل نمونههایی که در فرآیند آموزش مشاهده نکرده عاجز باشد.
همانطور که ذکر شد، هر داده MNIST دو بخش دارد، یک تصویر از یک رقم دستنویس و برچسب مرتبط با آن.
ما از این پس تصاویر را “xs” و برچسبهای مرتبط را “ys” مینامیم. هر دو مجموعه آموزش و تست xs و ys دارند، برای مثال تصاویر آموزشی mnist.train.images و برچسبهای آموزشی mnist.train.images هستند.
اندازه هر تصویر ۲۸*۲۸ پیکسل است. ما میتوانیم هر تصویر را بهصورت آرایهای بزرگ از اعداد تفسیر کنیم:
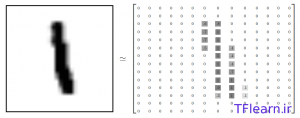
همچنین میتوان این آرایه را به یک بردار با اندازه ۲۸*۲۸=۷۸۴ تبدیل کرد. مهم نیست که ما آرایه را چگونه به بردار تبدیل کردیم، فقط باید همین روال را برای همه دادهها به یک صورت انجام دهیم.
اگر از این بعد به تصاویر MNIST نگاه کنیم، میتوانیم این بردارهای تصاویر MNIST را گروهی از نقاط در یک فضای برداری ۷۸۴ بعدی هستند. اگر این درک مطلب قدری برای شما دشوار است و یا تجسم این فضاها و دادهها قدری پیچیده به نظر میرسد، بهتر است سری به این پست بزنید که در آن مجموعه دادهی MNIST بصری سازی (Visualisation) شده است.
اما شاید سؤالی که برای شما نیز مطرح میشود، مسطح سازی دادهها بدون توجه به ساختار ۲بعدی تصاویر است. ممکن است شما نیز بر این باور باشید که این کار آنچنان روش خوبی نیست. بهترین روش بینایی ماشین برای بهرهبرداری از این ساختار (دوبعدی) تصاویر در مطالب بعدی توضیح داده خواهد شد. اما این عمل مسطح سازی برای روش سادهای که در این آموزش استفاده میشود (یعنی رگرسیون softmax است) بد نیست.
با اوصاف بالا، mnist.train.images یک تانسور است ( یک آرایهی n بعدی) با ابعاد [۵۵۰۰۰و۷۸۴] است.اندیس بعد اول بیانگر تصاویر و اندیس بعد دوم بیانگر پیکسلهای هر تصویر است. هر مقدار در یک تانسور پیکسلی در یک تصویر خاص است که شدت نور آن پیکسل بین ۰ و ۱ است. تصویر زیر تجسمی از این تانسور است.

برچسبهای مرتبط در MNIST اعدادی بین ۰ و ۹ هستند که بیانگر آن هستند که تصویر کدام رقم ارائهشده است. برای اهداف این آموزش، میخواهیم که برچسبهای ارقام به شکل ” بردارهای one-hot” باشند.
بردار one-hot برداری است در یک بعد ۱ و در بقیه ابعاد صفر است. در اینجا nامین رقم بهصورت برداری نمایش داده میشود که nامین بعد آن ۱است. یعنی برای مثال ۳ به صورت خواهد بود.به همین ترتیب مجموعه برچسبها(mnist.train.labels) یک آرایهای از اعداد است در ابعاد [۵۵۰۰۰, ۱۰] که به صورت شماتیک در شکل زیر مشاهده میکنید.

با توصیفهایی که صورت گرفت، حال شما آماده ساختن مدل خود هستید.
رگرسیون Softmax
ما میدانیم که هر تصویر در MNIST بیانگر یک رقم است، خواه این رقم صفر یا نه و یا هر رقم دیگری است. ما میخواهیم به یک تصویر نگاه کنیم و احتمال اینکه چه عددی میتواند باشد را بگوییم. برای مثال مدل ما ممکن است با نگاه به تصویر ۹، ۸۰% اطمینان داشته باشد که تصویر ۹ است اما ۵% احتمال دهد که ۸ است (به خاطر تشابه دایرهی بالای ۹ لاتین با ۸ لاتین) و مقادیر کمی احتمال دهد که سایر ارقام نیز هست، چون کاملاً مطمئن نیست.
رگرسیون softmax یک مدل ساده و طبیعی است و اگر شما بخواهید احتمال بودن شی خاصی را به چیزی در میان چند چیز متفاوت اختصاص دهید، softmax ابزاری است که این کار را انجام میدهد. بعد از این، ما هر وقت ما مدلهایی با ظاهر پیچیده را آموزش دهیم ، گام نهایی یک لایه از softmax خواهد بود.
رگرسیون softmax دو گام دارد، ابتدا افزودن شواهدی (دلیلهایی) که ورودی را در کلاسهای خاصی قرار دهد و سپس تبدیل این شواهد به احتمالات است.
برای تطبیق دادن شواهد برای قرار دادن تصویر دادهشده در یک کلاس خاص، ما از جمع وزندار شدت نور پیکسلها استفاده میکنیم. اگر پیکسلی که شدت نور بالایی داشته باشد ، سندی است مبنی بر آنکه تصویر در آن کلاس قرا نمیگیرد و وزن مثبت است اگر آن سندی موردتوجه باشد.
شکل زیر وزنهایی را که یک مدل برای هر یک از این کلاسها یاد گرفته است، نشان میدهد. قرمز مقادیر وزنهای منفی را نشان میدهد و آبی بیانگر وزنهای مثبت است.
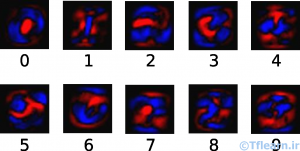
برای بهبود دقت، ما شواهد دیگری را اضافه نیز میکنیم که بایاس (bias) نامیده میشود. اساساً ما به دنبال این هستیم که بتوانیم بگوییم بعضی چیزها بیشتر مستقل از ورودی به نظر میرسند. درنتیجه گواه اینکه ورودی در کلاس قرار دارد عبارت است از:
$$\text{evidence}_i = \sum_j W_{i,~ j} x_j + b_i$$
که وزنها، مقدار bias برای کلاس و یک اندیس برای جمعکردن پیکسلهای تصویر ورودی ما است. سپس ما این شواهد را با استفاده از تابع softmax به احتمالات پیشبینیشده تبدیل میکنیم.
$$y = \text{softmax}(\text{evidence})$$
در اینجا softmax به عنوان یک تابع “فعالسازی” یا “اتصال” به کار میرود و خروجی تابع خطی ما را به شکلی که ما میخواهیم درمیآورد.—در این مورد تابع مذکور یک توزیع احتمالاتی بر روی ۱۰ مورد است. برای تجسم راحتتر softmax میتوان در نظر گرفت که تعدادی اسناد و شواهد را به احتمال اینکه ورودی ما در کدام کلاس قرار میگیرد، تبدیل میکند و به صورت زیر تعریف میشود:
$$\text{softmax}(x) = \text{normalize}(\exp(x))$$
که اگر این معادله را بسط دهید، خواهید داشت:
$$\text{softmax}(x)_i = \frac{\exp(x_i)}{\sum_j \exp(x_j)}$$
اما اغلب بهتر است که به softmax به این صورت نگاه کنید که ابتدا ورودی خود را به توان میرساند و سپس آن را نرمال میکند. به توان رساندن به این معنا است که یک واحد شهودات بیشتر، وزن داده شده به هر فرض را به صورت ضربی افزایش میدهد و بالعکس داشتن یک واحد کمتر از مشهودات، کسری از وزن قبلی خود را میگیرد. هیچ فرضی هرگز وزن صفر یا منفی ندارد. سپس softmax با جمعکردن یک با آنها و تبدیل به شکل یک توزیع احتمالاتی معتبر(درست)، این وزنها را نرمالسازی میکند.( برای درک بهتر از تابع softmax ، بخشی از کتاب Michael Nielsen را نگاه کنید)
برای درک راحتتر رگرسیون softmax ، میتوانید آن را شبیه شکلی که در پایین آورده شده است مجسم کنید، (گرچه در این مسئله باید با xهای بیشتر تجسم شود). برای هر خروجی ما یک مجموع وزندار از xها را حساب میکنیم، بایاس را میافزاییم و سپس softmax را اعمال میکنیم.
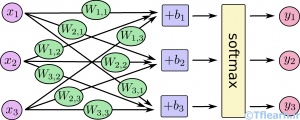
اگر ما خروجی آن را برحسب معادلات بنویسیم ، خواهیم داشت:
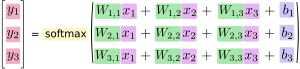
میتوان رویه مذکور را به صورت برداری درآورد، یعنی به یک ضرب ماتریسی و جمع برداری تبدیل کنیم.( راه مفیدی برای تجسم کردن است)

به صورت فشرده تر، میتوان نوشت:
$$y = \text{softmax}(Wx + b)$$
پیادهسازی رگرسیون در تنسورفلو
برای انجام کارای محاسبات عددی در پایتون ، معمولاً کتابخانههایی شبیه NumPy را استفاده میشود که محاسبات سنگینی مانند ضرب ماتریسها را در خارج از پایتون با مؤثرترین کدهای پیادهسازی شده در سایر زبانهای برنامهنویسی انجام میدهد .
متأسفانه ممکن است سربار محاسباتی زیادی از این تعویض محیط در هر عملیات محاسباتی اتفاق بیافتد. این سربار بهخصوص زمانی سنگینتر میشود که بخواهید محاسبات را بر روی چند GPU یا در یک سیستم توزیعشده انجام دهید که علاوه بر هزینههای جابجایی بین محیطها، میتواند هزینه بالای انتقال دادهها را نیز در برداشته باشد.
گذشته از اینکه TensorFlow بیرون از پایتون بار سنگین محاسباتی خود را دارد، اما پیش از آن، گامی برای جلوگیری از این سربار تعویض محیط برمیدارد.
بهجای اجرای یک دستور پرهزینه مستقل از پایتون، TensorFlow به ما این امکان را میدهد یک گراف از تعامل و روابط عملیات را توصیف کنیم که یکجا در خارج پایتون اجرا شوند. (چنین رهیافتی در کتابخانههای یادگیری ماشین نظیر theano و torch نیز دیده میشود.)
خوب برای استفاده از TensorFlow ما باید آن را فراخوانی کنیم :
import tensorflow as tfما این تعاملات عملگرها را با دستکاری نمادین متغیرها توصیف میکنیم. یعنی بااینکه متغیرها و… ایجاد میکنیم، اما مادامیکه در یک جلسه (Session) اجرا نشوند، هیچ مقداری به وجود نمیآید.
اجازه دهید یکی از آنها را ایجاد کنیم:
x = tf.placeholder(tf.float32, [None, 784])x یک مقدار خاص نیست، بلکه یک ظرف (placeholder) است، مقدار آن را زمانی که از TensorFlow بخواهیم یک محاسبه انجام دهد، وارد خواهیم کرد.
ما میخواهیم که قادر باشیم هر تعداد دلخواه از تصاویر MNIST که به بردار ۷۸۴ بعدی مسطح شدهاند وارد کنیم.
ما این موضوع را به صورت یک تانسور دوبعدی از اعداد ممیز شناور نمایش میدهیم که به شکل [None, 784] هستند. (منظور از None این است که طول این بعد میتواند هر چیزی باشد)
ما همچنین وزنها و بایاسها را برای مدلمان نیاز داریم . میتوانیم درمان این کار را با ورودیهای اضافی تصور کنیم ، اما TensorFlow راه بهتری برای مدیریت آن دارد:
متغیرها
یک متغیر (Variable) تانسور قابل ویرایشی است که در گراف محاسباتی عملگرهای TensorFlow وجود دارد، میتواند در جریان محاسبات استفاده یا مورد تغییر قرار گیرد. برای برنامههای یادگیری ماشین بهطور عمده پارامترهای یک مدل Variable هستند.
W = tf.Variable(tf.zeros([784, 10]))b = tf.Variable(tf.zeros([10]))
ما این متغیرها را با مقداردهی اولیه ایجاد میکنیم. در اینجا ما هر دوی W و b را با تانسورهایی از صفر مقداردهی اولیه کردیم. تا وقتی که ما قصد یادگیری W و b را داریم، اصلاً مهم نیست که مقدار اولیه آنها چه باشد.
یادآوری میکنیم که W به شکل [۷۸۴, ۱۰] بعدی است، چرا که ما میخواهیم بردارهای تصویر ۷۸۴ بعدی را در آن ضرب کنیم تا بردارهای ۱۰بعدی (اسناد و ادله) را برای کلاسهای مختلف ایجاد کنیم. b نیز به شکل [۱۰] است که ما میتوانیم آن را به خروجی اضافه کنیم.
حال ما میتوانیم مدلمان را پیادهسازی کنیم. این کار به اندازه فقط یک خط کد است!
y = tf.nn.softmax(tf.matmul(x, W) + b)
ابتدا ما x را در W با عبارت
1 | tf.matmul(x, W) |
ضرب میکنیم. همانطور که تا الآن مشاهده کردید، از زمان نصب تنسورفلو با چند خط کد ساده تا این لحظه که مدل خود را ایجاد کردید، فقط چند خط کد ساده استفاده کردید. چون تنسورفلو بهگونهای طراحیشده است که ساخت یک رگرسیون softmax را بهطور خاصی آسان کند. تنسورفلو یک راه بسیار انعطافپذیر برای توصیف انواع محاسبات عددی اعم از مدلهای یادگیری ماشین تا شبیهسازیهای فیزیکی و یادگیری عمیق است و با یک بار تعریف مدل میتوان آن را در دستگاههای مختلف اجرا کرد یعنی بر روی CPU کامپیوترتان، GPUها و حتی پردازنده موبایلها!
آموزش مدل
برای آموزش مدل، نیاز است که مشخص کنیم که چه چیزی مدل را بهبود میبخشد. خوب درواقع در یادگیری ماشین ما، بهطور عمده آنچه را که باعث بد شدن مدل است، تعریف میکنند که هزینه یا زیان نامیده میشود و سپس تلاش میکنند که بد بودن آن را کمینه کنند.اما در نهایت دو جمله بالا به یک معنا است، چه تابع زیان کمینه شود و یا چه تابع سود بیشینه گردد.
یکی از رایجترین و بهترین توابع هزینه یا زیان cross-entropy است.
cross-entropy به طور قابل ملاحظهای بر خواسته از تفکر در زمینه کدهای فشردهسازی اطلاعات در نظریه اطلاعات است اما به یک ایده مهم در بسیاری از زمینهها تبدیلشده است ، از شرطبندی گرفته تا یادگیری ماشین . این تابع به صورت زیر تعریف میشود:
که توزیع احتمالاتی پیشبینیشدهی ما است و توزیع درست است.( که در اینجا بردار one-hotای است که ما به ورودی خواهیم داد). در قسمتی از کار، cross-entropy میزان غیر مؤثر بودن پیشبینی ما را برای توصیف حقیقت (درستی) اندازهگیری میکند یعنی چه میزان از عددهایی را که دیده بودن اشتباه گفته بودیم.
برای پیادهسازی cross-entropy ابتدا ما باید یک placeholder جدید اضافه کنیم تا جوابهای صحیح را وارد آن نماییم.
y_ = tf.placeholder(tf.float32, [None, 10])
سپس ما میتوانیم cross-entropy را به صورت پیاده سازی کنیم:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))ابتدا
1 | tf.log |
لگاریتم هر المان از y را محاسبه میکند. سپس ما هر المان از _Y را با المان مرتبط اش از
1 | tf.log (y) |
ضرب میکنیم.
سپس tf.reduce_sum المانهای بعد دوم y را بنا بر پارامتر reduction_indices=[1] اضافه میکند .
در نهایت
1 | tf.reduce_mean |
میانگین همه نمونههای موجود در دسته را حساب میکند.
حال که ما میدانیم که مدلمان چه کاری میخواهد انجام دهد، بسیار آسان است که با TensorFlow آن را آموزش دهیم. چون تنسورفلو داخل گراف محاسباتیاش را میداند و میتواند به طور خودکار الگوریتم پس انتشار(backpropagation) را برای تعیین کارای چگونگی تأثیر متغیرهای بر تابع هزینهای که میخواهید کمینهاش کنید ،استفاده کند. سپس میتوانید برای تغییر متغیرها و کاهش هزینه، الگوریتم بهینهسازی را انتخاب کنید.
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
در اینجا ما میخواهیم که تنسورفلو cross_entropy را با استفاده از الگوریتم گرادیان نزولی با نرخ آموزش ۰٫۵ کمینه کند. گرادیان نزولی روش سادهای است که تنسورفلو بهسادگی هر متغیر را مقدار کوچکی در جهت کاسته شدن هزینه جلو میبرد. همچنین تنسورفلو الگوریتمهای بهینهسازی بسیار دیگری را تعبیه کرده که استفاده از آنها بهسادگی یک خط کد است.
آنچه تنسورفلو در پشتصحنه این کار انجام میدهد؛ در حقیقت افزودن عملیات جدیدی به گراف محاسباتی است که پس انتشار و گرادیان نزولی را پیادهسازی میکند.
حالا ما مدلمان را آماده آموزش کردهایم. فقط یکچیز قبل انجام فرآیند آموزش مدل باید انجام داد که ما مجبوریم یک عملیات برای مقداردهی اولیه متغیرهایی که ایجاد کردهایم، اضافه کنیم.
init = tf. global_variables_initializer()توجه کنید که این کد، فرآیند مقداردهی اولیه را تعریف میکند ولی این کار را انجام نمیدهد(اجرا نمیکند)
حالا ما میتوانیم مدل را در یک جلسه (Session) راهاندازی کنیم و عملیاتی را که متغیرها را مقداردهی اولیه میکند اجرا کنیم.
sess = tf.Session()sess.run(init)
حال بیاید مدل آموزش دهیم. ما گام آموزش را ۱۰۰۰ مرتبه اجرا خواهیم کرد.
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})هر گام از حلقه ، ما یک دسته از ۱۰۰ نقطه (تصویر) تصادفی مجموعه آموزشیمان را برمیداریم . با مقداردهی ظرفها (placeholders) با استفاده از دیکشنری دستههای دادههای آموزشی، train_step را اجرا میکنیم تا فرآیند آموزش آغاز شود. (توجه کنید که منظور از دیکشنری دادهها، داده ساختار dictionary پایتون است که این امکان را فراهم میکند که به سهولت مشخص کنیم چه دادههایی باید وارد ظرفهای موردنظرمان شود)
آموزش مدل با استفاده از دستههای کوچک از دادههای تصادفی، «آموزش تصادفی» نامیده میشود. ( که در اینجا به خاطر استفاده از الگوریتم گرادیان نزولی، گرادیان نزولی تصادفی گفته میشود). بهطور ایدئال ما دوست داریم که همه دادهها را برای هر گام از آموزش استفاده کنیم چرا که دید بهتری از آنچه باید انجام دهیم، میدهد. اما این امر بسیار هزینهبر است. پس ما بهجای این کار، یک زیر مجموعه متفاوت از دادهها را هر بار استفاده میکنیم. انجام این کار کمهزینهتر است و نسبت به حالت استفاده از همه دادهها سود یکسانی میرساند.
ارزیابی مدل
مدل ما چقدر خوب کار میکند؟ سؤال بسیار مهمی که عملاً در مسئلات یادگیری ماشین، پس از ارائه یک مدل مطرح میشود.
خوب ، ابتدا بیاید متجسم شویم که ما برچسب درست را پیشبینی کردهایم.
tf.argmax یک تابع بسیار مفید است که اندیس بالاترین ورودی در تانسور در طول محورها به شما میدهد. برای مثال در این مسئله برای هر ورودی، tf.argmax(y,1) برچسبی را که مدل ما فکر میکند بسیار شبیه ورودی است بازمیگرداند ، درحالیکه tf.argmax(y_,1) بیانگر برچسب صحیح است. ما میتوانیم tf.equal را برای کنترل صحت تطابق پیشبینیهایمان استفاده کنیم.
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))این کد فهرستی از مقادیر بولین (صفر یا یک) را به ما میدهد. برای تعیین اینکه چه کسری صحیح است، ما آنها را به نوع شناور ممیزی تبدیل میکنیم و میانگین آنها را میگیریم. برای مثال [True, False, True, True] خواهد شد [۱,۰,۱,۱] که با توجه به حرفهای بالا، میانگین آن ۰٫۷۵ است.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
درنهایت دقت دادههای آزمون را حساب میکنیم.
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))که باید حدود ۹۲% باشد.
آیا این مقدار دقت خوب است؟ در حقیقت نه! بلکه بسیار هم بد است! این دقت بدین دلیل است که ما مدل سادهای را استفاده کردهایم. با چند تغییر کوچک، میتوانیم این مقدار را به ۹۷% برسانیم. بهترین مدلها میتوانند بهدقت بیش از ۹۹٫۷% نیز برسند. در آموزشهای و مقالات بعدی، گامهایی در جهت نیل به این مقدار خواهیم برداشت. پس حتماً مطالب بعدی را نیز دنبال کنید.

برادر اگه وقت کردین بازم مطلب بذارین
خدا قوت بسیار عالی بود مطالبتون
سلام و عرض ادب.
ممنون از مطالب ارزشمندی که قرار میدید
من در محیط jupyter کدها رو اجرا کردم ولی هیج نتیجه ای نمایش داده نمیشه به جز اینکه اعلام میکنه دیتاست دانلود شده
این طبیعی یا یه جای کارم اشکال داره
ممنون
پاسخ سوال خود را در این مطلب http://www.tflearn.ir/1395/11/13/interactive-session/ متوجه خواهید شد.
بسیار عالی
خوشحالم یکی از فارسی زبانان با این شور، علاقه و تبحر شروع به انتقال اطلاعات و دانش به همزبانانش کرده
موفق باشید
سپاسگزارم
عالی بود ممنونم
بسیار عالی و کاربردی! تشکر از زحمات شما
در صورت امکان شبکه های LSRM را هم به همین طریق آموزش بدهید.
سلام
البته بهتر هست برای ایمپورت مجموعه دیتای MNIST طبق توصیه Google CoLab از دیتای آپدیت شده اختصاصی استفاده بشه
یعنی بجای MNIST_DATA باید این آدرس باشه : official/mnist/dataset.py
من در Google CoLab تست کردم و جواب مثبت داد :
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Extracting official/mnist/dataset.py/train-images-idx3-ubyte.gz
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Extracting official/mnist/dataset.py/train-labels-idx1-ubyte.gz
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Extracting official/mnist/dataset.py/t10k-images-idx3-ubyte.gz
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting official/mnist/dataset.py/t10k-labels-idx1-ubyte.gz
W = tf.Variable(tf.zeros([784, 10]))b = tf.Variable(tf.zeros([10]))
رو هم بی زحمت تو دو تا سلول جدا می نوشتید بهتر بود چون تو یه خط هست بعضا گمان میشه باید تو یه سلول نوشت و ارور میده